Informath
Informath under the Hood
(c) Aarne Ranta 2025-2026
This document is a complement of the README file of Informath. It can be read independently to get an idea about the theory, but you can also start with installing the software and experimenting with it as described in the README.
This document serves two main purposes:
- practical: help you extend contribute to Informath in a deeper way, by editing the grammar and the source code
- theoretical: understand the theory behind Informath, its implementation, and its limitations
The Informath project
The Informath project addresses the problem of translating between formal and informal languages for mathematics. It aims to translate between multiple formal and informal languages in all directions:
- formal to informal (informalization)
- informal to formal (autoformalization)
- informal to informal (translation, via formal)
- formal to formal (works in special cases)
The formal languages included are Agda, Rocq (formerly Coq), Dedukti, and Lean. The informal languages are English, French, German, and Swedish. The goal of Informath is
- to enable complete informalizations of formalisms expressible in Dedukti,
- generate and analyse informal mathematical language in all of its variations.
The latter goal is inspired by Mohan Ganesalingam’s The Language of Mathematics (2013).
Here is an example statement involving all of the currently available languages. The Dedukti statement has been used as the source of all the other formats. Also any of the natural languages could be used as the source:
Dedukti: prop110 : (a : Elem Int) -> (c : Elem Int) ->
Proof (and (odd a) (odd c)) ->
Proof (forall Int (b => even (plus (times a b) (times b c)))).
Agda: postulate prop110 : (a : Int) -> (c : Int) ->
and (odd a) (odd c) ->
all Int (\ b -> even (plus (times a b) (times b c)))
Rocq: Axiom prop110 : forall a : Int, forall c : Int,
(odd a /\ odd c -> forall b : Int, even (a * b + b * c)) .
Lean: axiom prop110 (a c : Int) (x : odd a ∧ odd c) :
∀ b : Int, even (a * b + b * c)
-
English: Prop110. Let $a$ and $c$ be integers. Assume that $a$ and $c$ are odd. Then $a b + b c$ is even for all integers $b$.
-
French: Prop110. Soient $a$ et $c$ des entiers. Supposons qu $a$ et $c$ sont impairs. Alors $a b + b c$ est pair pour tous les entiers $b$.
-
German: Prop110. Seien $a$ und $c$ ganze Zahlen. Nimm an, dass $a$ und $c$ ungerade sind. Dann ist $a b + b c$ gerade für jede ganze Zahl $b$.
-
Swedish: Prop110. Låt $a$ och $c$ vara heltal. Anta att $a$ och $c$ är udda. Då är $a b + b c$ jämnt för alla heltal $b$.
More formalisms and informal languages will be added later. Also the scope of language structures is at the moment theorem statements and definitions; proofs are included for the sake of completeness, but will require more work to enable more natural verbalizations.
The structure of Informath
The structure of Informath is shown in the following picture:
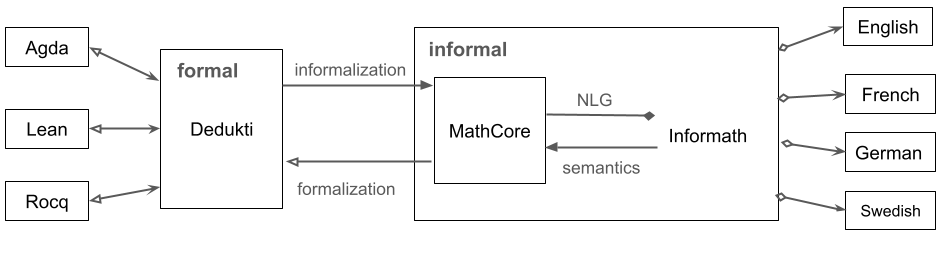
The diagram has four kinds of arrowheads. Solid ones mean that the operation is a total function, giving exactly one result for every input (triangular arrowheads) or possibly many (diamond). Hollow arrowheads mean partial functions which can likewise give at most one result (triangular) or many results (diamond):
- Conversions from Dedukti to Agda, Rocq, and Lean are partial, because Dedukti is more permissive than these formalisms.
- Conversion from MathCore to Dedukti may fail because MathCore is more permissive than Dedukti; this is because we delegate dependent type checking to Dedukti.
- Conversion from MathCore to Informath is one-to-many, and always results in at least one value, the MathCore expression itself.
- Conversions from English and other natural languages to Informath may fail, because the input is not covered by the grammar. They can also give many results, because the grammar accepts ambiguity; the idea is that ambiguity is ultimately checked on semantic grounds in Dedukti.
Conversions between MathCore and Informath, and extending the Informath language itself, are the most open-ended parts of the project and hence the main research focus.
Conversions from Dedukti to Agda, Coq, and Lean and back are mostly engineering (although tricky in some cases) that has to a large extent been done for the kind of code needed in Informath. Conversions from these type theories to Dedukti rely on already existing third-party tools. Those tools are not always up to date with the latest versions of the systems, but they have their own development teams that have goals independent of Informath.
Dedukti
Dedukti is a minimalistic logical framework aimed as an interlingua between different proof systems such as Agda, Rocq (formerly Coq), Isabelle, and Lean. Its purpose is to help share formalizations between these systems. Dedukti comes with an efficient proof checker and evaluator. Translations from many other proof system to Dedukti have been built, and this work is ongoing.
Technically, Dedukti is described as an implementation of Lambda-Pi-calculus with rewrite rules. It is similar to Martin-Löf’s logical framework from the 1980’s, except for a more liberal syntax of rewrite rules. Thereby, it is also similar to the ALF system of 1990’s and to the abstract syntax of GF, Grammatical Framework.
Due to its simplicity and expressivity, together with a powerful implementation and existing conversions from other formalisms, we have chosen Dedukti as the interlingua for formal proof systems.
The syntax of Dedukti
The complete grammar of Dedukti used in Informath is defined in Dedukti.bnf. In this section, we will give an overview aimed to help get started.
Type theory, as defined for instance by Martin-Löf 1979, has four forms of judgement:
- A : Type
- A = B : Type, where A and B are types
- a : A, where A is a type
- a = b : A, where A is a type and a, b : A
In Dedukti, all of these can be expressed syntactically by just two forms,
a : A.
def a : A := b.
because Type is itself a type. Dedukti also has some other forms of judgements, in particular
[x, y, z ...] a := b.
for rewrite rules. They can be used for definitions by cases, where $a$ is a pattern that matches certain expressions where the variables $x, y, z, \ldots$ may occur. The def form of judgement is actually syntactic sugar for a combination of a typing judgement and a single rewrite rule without variables:
def a : A.
[] a := b.
The other forms of judgement in Dedukti, using keywords thm and inj instead of def, need not concern us here. They are only different in how they are handled in computations and not how they express mathematical content.
The parts of judgements are expressions, of some of the following forms:
Ident (; variable, constant ;)
Exp Exp (; application ;)
Ident => Exp (; abstraction ;)
(Ident : Exp) -> Exp (; dependent function type ;)
Exp -> Exp (; non-dependent function type ;)
(Ident : Exp := Exp) => Exp (; local definition ;)
Comments in Dedukti are enclosed between (; and ;).
Here are some examples of how Dedukti has been used in Informath:
Set : Type.
Prop : Type.
Elem : Set -> Type.
Proof : Set -> Type.
false : Prop.
and : Prop -> Prop -> Prop.
or : Prop -> Prop -> Prop.
if : Prop -> Prop -> Prop.
def not : Prop -> Prop := A => if A false.
forall : (A : Set) -> (Elem A -> Prop) -> Prop.
exists : (A : Set) -> (Elem A -> Prop) -> Prop.
Num : Set.
plus : Elem Num -> Elem Num -> Elem Num.
Eq : Elem Num -> Elem Num -> Prop.
For more examples, we recommend to start with BaseConstants.dk.
Identifiers and numerals
The use of identifiers as expressions has been applied in all example above but not been explained yet. In Dedukti, idenfifiers include both variables and constants and even numeric literals. Dedukti has no built-in type of literals, but they can be declared and/or defined as identifiers or combinations of them. In the Informath project, we have mostly (but not exclusively) used types Dig and Num with the following rules:
Dig : Set.
0 : Dig.
1 : Dig.
2 : Dig.
(; similarly for 3, 4, 5, 6, 7, 8, 9 ;)
Num : Set.
nd : Dig -> Num.
nn : Dig -> Num -> Num.
Thus for instance $1987$ is expressed by
nn 1 (nn 9 (nn 8 (nd 7)))
If you are used to a rigorous treatment of different classes of numbers (natural, integer, rational, real, complex), you will now ask how these are treated in Dedukti and Informath. The answer is that Dedukti itself says nothing about them, because it has no built-in numbers. Thus one has either to build the different number classes from scratch or to inherit them from some other formalism by a conversion. A typical starting point is then natural numbers starting from 0 and extended by a successor function,
0 : Elem Nat.
succ : Elem Nat -> Elem Nat.
The other digits can then be defined
def 1 : Elem Nat := succ 0.
def 2 : Elem Nat := succ 1.
and so on. Integers and rational numbers are typically encoded as pairs. For example, integers are sometimes encoded with the function
int : Elem Nat -> Elem Nat -> Elem Int
so that int x y represents $x - y$. Real numbers have many alternative definitions, also depending on whether classical or constructive mathematics is followed.
In the current use of Dedukti in Informath, we have chosen an approach known as soft typing, relying on just one Dedukti type, Num, of numbers. This is because we are interested in modelling informal mathematical language, where, contrary to foundational treatments, numbers can be considered as one and the same type, at least from the syntactic point of view. Thus, for instance, $1987$ is both a natural number, an integer, and a rational and a real and a complex number, despite their different formalizations in ZF set theory or in constructive type theory. Soft typing is known from some other formal systems, in particular Mizar (REF), which treats expressions such as “real” and “rational” as predicates over an untyped universe of entities.
The treatment of numbers as a single type is one of the points Ganesalingam argues for in his Language of Mathematics, because he sees it as the best fitting account of the actual usage of language in informal mathematics. The price we have to pay are complex details in translating between Dedukti and other type theories (Agda, Lean, Rocq). Each of them has its own views about what expressions and operators can be used for different number classes, and different kinds of coercions are needed to match these views. A typical coercion is
def nat2int : Nat -> Int := n => int n 0.
In Dedukti, the definition could also be simply
nat2int := n => n.
if Nat and Int are treated as synonyms of Num.
Then this coercion is not even needed. However, when translating to another system, a natural number to which an integer operation is applied may be need to be wrapped in a coercion function that is defined in that system.
We do not know yet all the pros and cons of an underspecifird treatment of number classes with soft typing. However, the differences between other formalisms and theories can be seen as another argument for maintaining an underspecified treatment of number types in Dedukti when used as an interlingua between those systems.
Correctness
The fundamental notion of correctness in type theory is type-correctness: that an expression $a$ really has the type $A$. By to the propositions as types principle, type correctness also covers the correctness of proofs with respect to a given proposition.
Type correctness is defined by a set of typing rules, which in software are implemented in a type checker. Typing rules are defined for judgements of the form
\[\Gamma \vdash a : A\]where $\Gamma$ is a context, which assigns types to identifiers (i.e., variables and constants). The simplest typing rule is
\[\Gamma \vdash x : A, \text{if $x : A$ is in $\Gamma$}\]for identifier expressions $x$. Application expressions have the rule
\[\frac{\Gamma \vdash f : (x : A) \rightarrow B \hspace{4mm} \Gamma \vdash a : A}{\Gamma \vdash f a : B(x := a)}\]where the metanotation $B(x := a)$ means that $a$ is substituted for $x$ in $B$. If $B$ really is a dependent type that varies in $x$, this rule can assign different types to applications of $f$ to different arguments.
Finally, we have the typing rule for abstraction, where the context changes between the premisses and the conclusion:
\[\frac{\Gamma, x : A \vdash b : B}{\Gamma \vdash x \Rightarrow b : (x : A) \rightarrow B}\]Under the propositions as types interpretation, this rule models proofs by assumption: if we can prove $B$ under the assumption $x : A$, then we can prove $B$ for every element or $A$. Seeing both $A$ and $B$ as propositions, this rule corresponds to proving the implication from $A$ to $B$. If $A$ is seen as a type and $B$ as a proposition depending on $x$, this rule corresponds to proving a universal statement from the assumption that $x$ is and arbitrary object of $A$.
The three typing rules look simple and natural. But this simplicity is deceptive, because we also have the rule
\[\frac{\Gamma \vdash a : A \hspace{4mm} \Gamma \vdash A = B : Type}{\Gamma \vdash a : B}\]This rule also looks simple and natural, but it is impossible to follow in full generality. The reason lies in the undecidability of the halting problem: The equality of the types $A$ and $B$ is usually checked by normalization, that is, by computing both expressions to a normal form and checking that the result is the same for both $A$ and $B$. However, computation in Dedukti includes execution of rewrite rules. Since the rewrite rules form a Turing-complete language, there is no general guarantee that their execution terminates. Because of this, equality checking - and hence type checking - is undecidable.
Agda, Rocq, and Lean
Agda, Rocq, and Lean are type-theoretical proof systems just like Dedukti. But all of them have a richer syntax than Dedukti, because they are intended to be hand-written by mathematicians and programmers, whereas Dedukti has an austere syntax suitable for automatic generation for code.
Translators from each of Agda, Rocq, and Lean to Dedukti are available, and we have no plans to write our own ones. However, translators from Dedukti to these formalisms are included in the current directory. They are very partial, because they only have to target fragments of the Agda, Rocq, and Lean. This is all we need for the purpose of autoformalization, if the generated code is just to be machine-checked and not to be read by humans.
However, if Informath is to be used as an input tool by Agda, Rocq, and Lean users, nice-looking syntax is desirable. In the case of Rocq and Lean, we have tried to include some syntactic sugar, such as infix notations. In Agda, this has not yet been done, because its libraries and the syntactic sugar defined in them are not as standardized as in Rocq and Lean.
Another caveat is that Dedukti is, by design, more liberal than the other systems. Type checking of code generated from type-correct Dedukti code can therefore fail in them. This can sometimes be repaired by inserting extra code such as coercions, but this is still mostly future work.
If you want to check the formal code in any of the proof systems, you must also install them. Informath itself does not require them, but at least Dedukti is useful to have so that you can check the input and output Dedukti code. Here are the links to them:
Layers of natural language grammars
In the Informath diagram above, the “Informal” part has a subpart called MathCore. It is related to the full Informath by two operations: NLG, which produces alternatives for MathCore expressions, and semantics, which translates all these expressions back to their “normal” MathCore forms. All communication with Dedukti takes place via MathCore, while actual natural language is generated from and parsed to the full Informath. Inside the “Formal” and “Informal” boxes, all operations are defined on the level of abstract syntax trees.
The following subsections give a birds-eye view of the two languages and their design goals, while the technical details will be given later, after a short introduction to Grammatical Framework, the grammar formalism in which they are implemented.
MathCore
The MathCore language is meant to be the “core abstract syntax” in Informath. Technically, it is just a subset of Informath: Informath is implemented by adding an extension module to MathCore.
As shown in the picture above, informalization and autoformalization are in the first place defined between Dedukti and MathCore. On the type theory side, this is composed with translations between other frameworks and Dedukti. On the natural language side, mappings between MathCore and the full Informath are defined on an abstract syntax level of these languages. Input and output of actual natural languages is performed by generation and parsing with the concrete syntaxes of each language.
At this point, it should be enough to say that an abstract syntax consist of trees, whereas a concrete syntax is a mapping between such trees and the strings of some language. Performing operations on the abstract syntax makes them shareable between multiple languages, which is the very idea of Grammatical Framework (GF), the grammar formalism that Informath uses. The section on GF will give the full details of these concepts.
MathCore is a minimalistic grammar for mathematical language, based on the following principles:
- Completeness: all Dedukti code can be translated to MathCore.
- Non-ambiguity: all MathCore text has a unique translation to Dedukti.
- Losslessness: MathCore is a lossless representation of Dedukti; that is, all Dedukti code translated to MathCore can be translated back to the same Dedukti code (modulo some differences such as renaming of variables).
- Traceability: Dedukti code and MathCore text can be aligned part by part.
- Grammaticality: MathCore text is grammatically correct natural language (with mathematical symbols and some mark-up such as parentheses to prevent ambiguity).
- Naturalness: MathCore supports natural expressions for mathematical concepts using nouns, adjectives, verbs, and other structures conventionally used in mathematical text.
- Minimality: MathCore is defined to have exactly one way to express each Dedukti judgement. Alternative ways are provided in Informath via NLG. Typically, the unique way is the most verbose one. For example, complex mathematical expressions are given in their verbal forms (“the sum of $x$ and $y$”) rather than formulas (“$x + y$”), because formulas are not available when any of the constituents if not formal (“$x +$ the successor of $y$”).
- Extensibility: MathCore can be extended with lexical information assigning natural language verbalizations to Dedukti identifiers.
- Multilinguality: MathCore has been implemented by GF RGL and is therefore ready for concrete syntax in new languages.
The following propertes are, however, not expected:
- Type correctness: MathCore expressions can be semantically invalid, leading to syntactically correct Dedukti code that is rejected by Dedukti’s type checker; this is because the type system is weaker and lacks dependent types
- Fluency: MathCore text can be repetitive and hard to read; making it better is delegated to the Informath grammar via the NLG component.
- Compositionality: The translation between Dedukti and MathCore is not compositional in the strict sense of GF, as the two languages have different abstract syntaxes. MathCore has a larger set of syntactic categories than Dedukti, for instance distinguishing between expressions that represent kinds, objects, propositions, and proofs.
- Easy natural language input: while the grammar of MathCore is reversible, it is tedious to write MathCore. It is intended to be generated automatically: by conversion from Dedukti on one hand and from Informath on the other.
The rationale of this design is modularity and an optimal use of existing resources:
- Type checking is delegated to Dedukti.
- Conversions to different frameworks are also delegated to Dedukti.
- Variation of natural language input and output is delegated to full Informath.
Informath
Informath has been inspired by controlled natural languages (CNLs) such as ForTheL and Naproche and aims to cover most of them as subsets. But Informath also differs from traditional CNLs in several ways:
- Grammaticality: Informath follows the agreement rules of English (and other languages) instead of allowing free variation of e.g. singular and plural forms (as ForTheL and early versions of Naproche); this makes it more usable as the target of informalization.
- Ambiguity: CNLs prevent syntactic ambiguities by means of devices such as brackets and precedence rules. Informath tries to capture all syntactic ambiguities that exist in natural language, and delegates it to the logical framework to resolve them by semantic checking. This is in line with the findings of Ganesalingam’s Language of Mathematics, showing that informal mathematics is syntactically ambiguous but disambiguated by semantic clues.
- LaTeX: The original ForTheL is plain text, whereas Informath (like later versions of ForTheL and also Naproche) allows the full use of LaTeX similar to usual mathematical documents; this is one of the
- Extensions: Informath is open for extensions with new forms of expression when encountered in mathematical text. In ForTheL, new concepts can be defined, but the overall syntax is fixed. Because of the design of Informath, every extension is equipped with a new semantic rule that converts it to MathCore and thereby to Dedukti.
- Omissions: Informath is not guaranteed to cover everything that occurs in different CNLs. In particular, constructs that differ from grammatical English are usually omitted.
- Multilinguality: Informath has several concrete syntaxes sharing a common abstract syntax.
An example of variations
Consider again the example Dedukti statement used above:
Dedukti: prop110 : (a : Elem Int) -> (c : Elem Int) ->
Proof (and (odd a) (odd c)) ->
Proof (forall Int (b => even (plus (times a b) (times b c)))).
The MathCore informalization (in English) is one-to-one and verbose:
- Prop110. Let $a$ and $c$ be instances of integers. Assume that we can prove that $a$ is odd and $c$ is odd. Then we can prove that for all integers $b$, the sum of the product of $a$ and $b$ and the product of $b$ and $c$ is even.
MathCore renderings are designed to be unique for each Dedukti judgement. But the full Informath language recognizes several variations. Here are some of them for English, as generated by the system; other languages have equivalents of each of them:
- Prop110. For all integers $a$ and $c$, if $a$ is odd and $c$ is odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a$ and $c$ be integers. Then if $a$ is odd and $c$ is odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a , c \in Z$. then if $a$ is odd and $c$ is odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a$ and $c$ be integers. Assume that $a$ is odd and $c$ is odd. Then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a , c \in Z$. assume that $a$ is odd and $c$ is odd. Then for all integers $b$, $a b + b c$ is even.
- Prop110. For all integers $a$ and $c$, if both $a$ and $c$ are odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a$ and $c$ be integers. Then if both $a$ and $c$ are odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a , c \in Z$. then if both $a$ and $c$ are odd, then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a$ and $c$ be integers. Assume that both $a$ and $c$ are odd. Then for all integers $b$, $a b + b c$ is even.
- Prop110. Let $a , c \in Z$. assume that both $a$ and $c$ are odd. Then for all integers $b$, $a b + b c$ is even. Prop110. Let $a , c \in Z$. assume that both $a$ and $c$ are odd. Then $a b + b c$ is even for all integers $b$.
Some of the variants are stylistically better than others. For example, segments of the form “for all integers $b$, $a b + b c$ is even” where two different symbolic expressions are separated by only a comma are often considered bad style. Informath has a scoring system that gives penalties to such features, as well as to length and complexity (tree depth), resulting in a ranking of alternative informalizations.
Grammatical Framework
Grammatical Framework, GF is itself based on a logical framework (LF). To put it briefly,
- GF = LF + grammar
If you are already familiar with GF, you can skip this section. If not, it aims to give you the prerequisites needed to apply and extend the GF grammar of Informath.
GF as a logical framework: abstract syntax
The LF part of GF is called abstract syntax, and it is to a large extent similar to Dedukti: it has both dependent types and variable bindings, enabling higher-order abstract syntax. Thus one could in GF define the types of sets and props and a universal quantifier just like in Dedukti; here is the precise GF module:
abstract Logic = {
cat Set ;
cat Elem Set ;
cat Prop ;
cat Proof Prop ;
fun forall : (A : Set) -> (Elem A -> Prop) -> Prop ;
}
However, Informath grammars do not use all of these facilities, but only the fragmet known as context-free abstract syntax. In this syntax, the corresponding definitions look as follows:
abstract Logic = {
cat Set ;
cat Elem ;
cat Prop ;
cat Proof ;
cat Ident ;
fun forall : Set -> Ident -> Prop -> Prop ;
}
In this encodeing,
- the type dependencies (arguments of basic types) are omitted,
- abstractions are flattened to separate identifier and value arguments.
In this abstract syntax, a Dedukti expression of form
forall A (x => B)
is represented as
forall A x B
There are several reasons for using a context-free abstract syntax in Informath:
- grammar writing becomes more straightforward
- GF tools for dealing with dependent types and higher-order abstract syntax are less developed than for context-free abstract syntax
- ultimate type checking in Informath can be delegated to Dedukti and need not be performed in GF
- we can more easily deal with the overloading of expressions, which is ubiquitous informal mathematical language; giving every expression a precise but completely general type would be an overwhelming task
In the Logic modules above, we have already seen the syntax of GF’s abstract syntax: it uses modules with the keyword abstract in the header, and has two forms of judgement:
cat C
fun f : T
where (in context-free abstract syntax), the type T is either a category $C$ of a function type $C \rightarrow T$, where many-place functions are dealt by currying, like in Dedukti.
Concrete syntax
What makes GF into a grammar formalism is concrete syntax.
The simplest kind of concrete syntax is itself context-free: it consists of linearization rules that convert abstract syntax trees (terms of the logical framework) into strings.
This happens in a compositional fashion: a complex tree is linearized by concatenating the linearizations of its subtrees.
The following GF module defines a concrete syntax for Logic:
concrete LogicEng of Logic = {
lincat Set = Str ;
lincat Elem = Str ;
lincat Prop = Str ;
lincat Ident = Str ;
lincat Proof = Str ;
lin forall set ident prop =
"for" ++ "all" ++ ident ++ "in" ++ set ++ "," ++ prop ;
}
The operator ++ performs concatenation of token lists. The resulting strings typically have spaces between the tokens, but this depends on the unlexer applied to the token list. For example, the unlexer used in Informath will add a space after the comma "," but not before it.
The combination of the abstract syntax Logic with LogicEng is equivalent to a context-free grammar with the rule
Prop ::= "for" "all" Ident "in" Set "," Prop
In the opposite direction, the GF grammar can be seen as the result of taking apart pure constituency (the nonterminals) and surface realization.
This operation has several advantages.
The most obvious one is perhaps that one can vary the concrete syntax while keeping the abstract syntax constant.
For example, a corrsponding French grammar is obtained by changing the linearization rule of forall to
lin forall set ident prop =
"pour" ++ "tout" ++ ident ++ "dans" ++ set ++ "," ++ prop ;
A multilingual grammar is a grammar with one abstract syntax and several concrete syntaxes. It can be used for translation by parsing the source language into an abstract syntax tree and linearizing the tree into the target language. The abstract syntax then functions as an interlingua. Some of the languages could well be formal: a simple formalization and informalization system is obtained by writing a concrete syntax for the formal language:
lin forall set ident prop =
"forall" ++ set ++ "(" ++ ident ++ "=>" ++ prop ++ ")" ;
This approach has been used in e.g. Ranta 2011 (CADE) and Pathak 2024 (GFLean). While it gives a simple way to convert between formal and informal languages, it is limited by the requirement of compositionality: the linearization of a tree operates on the linearizations of its subtrees and cannot perform deeper pattern matching on the subtrees. Therefore, a GF abstract syntax cannot be shared by languages with very different structures. The approach followed in Informath is to have one abstract syntaxes for Dedukti and another one for Dedukti: surprisingly, natural languages are structurally close enough for this to work fine for them.
Concrete syntax beyond context-free
Much of the power of GF comes from not being context-free, but mildly context-sensitive. This class of languages is more restricted than fully context-sensitive (in the Chomsky hierarchy sense) and enjoys polynomial worst-case parsing complexity. It has turned out to be sufficient for almost any grammar-based analysis of natural languages, not only in GF but also with other formalisms such as TAG.
Some languages are strictly beyond context-free in the sense of weak generative capacity (generating the same sets of sentences). A simple example that we can deal with already is the copy language, the set of sentences consisting of two copies of the same string, where strings have an arbitrary length. In GF, this can be defined by the following simple rules:
cat S ;
fun copy : String -> S ;
lin copy s = s ++ s ;
using the built-in category String and leaving out the module structure.
Parameters
A more interesting question, in practice, is to see what one can do when leaving the limits of the context-free rule format.
This is in the first place expressed in the linearization types (keyword lincat).
Turning back to the Logic example, we can generalize the linearization type of Set by making it dependent on a parameter, grammatical number, which has values singular and plural.
This makes it possible to give both “integer” and “integers” the same abstract syntax.
Some constructs will need the singular form, some the plural.
Again leaving out the module structure, we can write
param Number = Sg | Pl ;
lincat Set = Number => Str ;
lin forall set ident prop =
"for" + "all" ++ set ! Pl ++ ident ++ "," ++ prop ;
with a new form of judgement for parameter type definitions, param.
They are in GF a special case of algebraic datatypes in languages like ML and Haskell, restricted to finite types (enumrations and their combinations).
The type Number => Str is a table type, whose objects are finite functions on parameter types, similar to inflection tables in traditional grammar.
The selection operator ! applies a table to an argument, selecting a valuel.
The above grammar is still context-free in the weak generative sense, because the Set category can be expanded to two non-terminals.
But this will in general also require a duplication of rules, whole number in the worst case is the produce of the numbers of parameters in the types involved.
Like many other grammars that use parameters, GF gives a compact way to produce sets of context-free rules.
Since parameter definitions belong to the concrete syntax, they can be different for different languages. French has also gender and mood, in addition to number:
param Number = Sg | Pl ;
param gender = Masc | Fem ;
param Mood = Ind | Subj ;
lincat Set = {s : Number => Str ; g : Gender} ;
lincat Prop = Mood => Str ;
lin forall set ident prop =
\\m => "pour" ++ tout ! set.g ++ set.s ! Pl ++ ident ++ "," ++ prop ! m ;
oper tout : Gender => Str = table {Masc => "tout" ; Fem => "toutes"} ;
The context-free expansion of the forall rule would here produce four rules, for each combination of the two genders with the two moods.
The code also shows a record type, combining a table with a gender in the linearization type of Set.
The keyword operintroduces yet another form of judgement: auxiliary operations. They are functions outside the fun/lin structure usable as auxiliaries in lin rules. The GF compiler eliminates them by inlining, and they are therefore unnecessary for the theoretical expression powerl. But they are an important part of grammar writing productivity, as they enable refactoring and reusability.
Discontinuous constituents
Linearization is not restricted to strings and tables that contain them: it can also produce discontinuous constituents, which are implemented as records containing severals strings and/or tables. Consider the following generalization of the English rules above:
lincat Set = {noun : Number => Str ; adverbial : Str}
lin forall set ident prop =
"for" + "all" ++ set.noun ! Pl ++ ident ++ set.adverbial ++ "," ++ prop ;
Many set expressions consist in this way of noun part, which is the head of the construction (in the linguistic sense), and an adverbial part. For example, “list of integers” consists of “list” and “of integers”. It is the head part that receives the plural ending, and variables are preferably placed between the two parts: “for all lists $l$ of integers”. This separation is what makes the expression discontinuous.
Summary of GF notation
While the abstract syntax notation of GF is familiar from logical frameworks, concrete syntax requires some explanations. We have in the above code examples used or presupposed the following:
- strings,
Str, more properly token lists- they are combined with concatenation
++, which unlike Haskell’s++“introduces a space” - but technically, the “space” is just a token boundary, which need not create an actual space character
- they are combined with concatenation
- record types e.g.
{s : Number => Str ; g : Gender} - table types e.g.
Gender => Str, a “finite function type” in the sense that the argument type must be a finite parameter type; the name comes from their typical usage to model inflection tables of words - tables (objects of table types), e.g. table {Masc => “tout” ; Fem => “toutes”}
- a special case is the table abstract
\\x => b, which just passes the parameter similarly to a lambda expression\x -> bbut builds a table (of some table type $P \Rightarrow B$) instead of a function (of some function type $A \rightarrow B$)
- a special case is the table abstract
- records (objects of record types), e.g.
{s = "ligne" ; g = Fem} - projections from record types, e.g.
set.g - selections from table types, e.g.
tout ! g- case expressions
case e of {...}are syntactic sugar fortable {...} ! e
- case expressions
This machinery - generalizing linearization types from strings with records and tables - has proven sufficient for many different languages, enabling them to share the same abstract syntax.
The GF Resource Grammar Library
The most substantial example of a multilingual GF grammar is the GF Resource Grammar Library (RGL), which at the time of writing includes over 40 languages. Its main significance for GF applications, including Informath, is that the programmer does not need to care about low-level linguistic features such as parameters, but can use the library instead. In particular, the application programmer seldom needs to use the table and record syntax shown in this section, but mostly just function calls to the RGL.
The RGL is divided into two main parts:
Syntax<LANG>, functions that form phrases from words and combine themParadigms<LANG>, functions that generate inflection forms of words
In addition, there are some smaller libraries, which are also used in Informath:
Prelude, basic operations on strings, analogous to Haskell’sPreludeFormal, operations for formal expressions, such as definitions of infix, prefix, and postfix operators with different precedencesSymbolic<LANG>, functions for using formal expressions as parts of verbal text
The suffix <LANG> it the 3-letter ISO 639-s (B) code for each language, e.g. Eng for English and Fre for French.
Most GF grammar names use these language codes, but this is just a recommendation, not a built-in feature of GF.
Starting with Syntax, the RGL provides a few dozen categories and functions.
The most important categories for Informath are the following:
Text, texts, consisting of many sentences, such as those for proofsS, sentences, with fixed tense (in Informath, usually present ) and polarity (positive or negative)Cl, clauses, atomic sentences consisting of a predicate (such as a verb or an adjective) with its arguments (subject, object, complements), unspecified as for tense and polarityVP, verb prases, verbs with their argument, such as “range from $a$ to $b$”NP, noun phrases, nouns with determiners and modifiers, such as “every even number” or singular terms such as “$x + y$”CN, common nouns, noun phrases without determiners, with variable number (admitting different determiners) but fixed gender, such as “natural number”AP, adjectival phrases, such as “uniformly continuous”, “even or odd”Adv, adverbial phrases, either single words such as “uniformly” or prepositional phrases such as “for every $x$”
The Paradigms functions build expressions of lexical categories, which contain individual words with their inflections and other properties such as gender and complement case:
N, nouns, such as “integer”A, adjectives, such as “even”V, verbs, such as “converge”V2, two-place verbs (including transitive verbs), such as “contain”Prep, prepositions, such as “for” (in some languages, also cases such as dative)Det, determiners, such as “the”, “every”Adv, adverbs, such as “everywhere”Conj, conjunctions, such as “and”, “either - or”
The Syntax API
Expressions of each of these categories are constructed with overloaded operations, that is, sets of operations where the one and the same name is used for different types of functions.
For ease of use and memory, the name of an RGL operation forming an expresion of category $C$ is almost always mk$C$ (but just almost because sometimes we need more than one operation of the same type).
Here are some that are widely used in Informath; for the full list, consult the RGL synopsis.
The synopsis gives an API consisting of a name, a type and an example, as we will also do here, using examples from Informath:
mkText : S -> Text We conclude that $f$ is continuous.
mkText : Text -> Text -> Text We have a contradiction. Hence $x$ is not prime.
mkS : (Polarity) -> S $x$ is (not) prime
mkCl : NP -> VP -> Cl $x$ is greater than $y$
mkCl : NP -> V -> Cl $f$ converges
mkCl : NP -> V2 -> NP -> Cl $l$ intersects $m$
mkCl : NP -> AP -> Cl $2$ is even and prime
mkVP : V -> VP converge
mkVP : V2 -> NP -> VP intersect $m$
mkVP : AP -> VP be even
mkNP : Det -> CN -> NP every natural number
mkCN : N -> CN number
mkCN : A -> N -> CN natural number
mkCN : AP -> CN -> CN uniformly continuous function
mkCN : CN -> Adv -> CN divisor of $24$
mkAP : A -> AP even
mkAP : Conj -> AP -> AP -> AP. even or odd
mkAdv : Prep -> NP -> Adv for every number
the_Det : Det the (number)
thePl_Det : Det the (numbers)
a_Det : Det a number
aPl_Det : Det (numbers)
every_Det : Det every (number)
and_Conj and
or_Conj or
for_Prep for
in_Prep in
The last items in the list show functions for structural words, which are a part of the Syntax modules.
They show another naming convention of the RGL: an English word and its category, separated by an underscore.
Despite the English name, they linearize to corresponding words in other langauges.
For instance, the_Det in French becomes “la” or “le” or “l’”, whereas thePl_Det becomes “les”.
Notice that the API contains, on purpose, redundancies.
For example, the CN “natural number” can be built with both of
mkCN (mkAP natural_A) (mkCN number_N)
mkCN natural_A number_N
Under the hood, the latter is defined in terms of the former, so there is no redundancy in the underlying core grammar. But the redundancies enable convenient shortcuts for the programmer.
The Paradigms API
The categories and functions in the Syntax API are defined for all languages in the RGL. This makes it straightforward to transfer code written for one language into another one. The morphological paradigms, however, are less portable, because the inflection tables and other grammatical features vary so much. Thus the noun inflection in English only needs a singular and a plural form, whereas in French also a gender is needed, and in German, four cases in both singular and plural. This is reflected in the variants of overloaded functions for each language.
In English, we have for instance
mkN : Str -> N number
mkN : Str -> Str -> N calculus, calculi
and in French,
mkN : Str -> N ligne (feminine, like most nouns ending -e)
mkN : Str -> Gender -> N ensemble (masculine)
In general, every language in the RGL has, for each lexical category, a smart paradigm that infers the inflection and other properties from just one string.
This is a qualified guess based on the characters contained in the string and statistics about the most common alternatives.
For examples, the mkN function of ParadigmsEng covers cases such as “number-numbers”, “bus-buses”, “baby-babies”.
But it does not cover “man-men”, “calculus-calculi”: for these words, the two-argument function has to be used.
The Informath grammar has an even higher level of API for defining vocabulary needed in mathematical functions and predicates. But in some cases, especially in languages other than English, the standard Paradigms API is needed in addition.
Libraries for formal code
Mathematical language is a mixture of words and symbols.
The symbolic part has its own syntactic features, familiar from grammars of programming languages and logical formalisms.
The RGL module Formal gives some useful categories and functions to define this part:
Prec, precedence levels (from 1 to 4)TermPrec, terms with a precedence levelinfixl : Prec -> Str -> TermPrec -> TermPrec -> TermPrec, terms built with left-associative infix operators.
The Symbolic API is used for combining symbolic terms with natural language expressions.
The following are used in Informath:
symb : Symb -> NPsymb : Symb -> SmkSymb : Int -> SymbmkSymb : Str -> Symb
The user of Informath, even when extending the grammar with new symbolism, rarely needs to consult these modules, because Informath gives a higher level API for introducing new symbolism.
Using the RGL
The RGL is normally installed in a place where the GF compiler can find it by referencing the variable GF_LIB_PATH.
With this information, it can find the library modules that are opened in other modules.
A typical usage is as follows. Let us first assume a simpler abstract syntax,
abstract Math = {
cat
Prop ; Set ; Elem ;
fun
AndProp : Prop -> Prop -> Prop ;
Nat : Set ;
Even : Elem -> Prop ;
}
Notice here a syntax feature of GF: a judgement keyword such as cat need not be repeated as long as judgements of the same form follow.
Now, an RGL-based concrete syntax
- opens
SyntaxandParadigmsmodules - uses RGL categories and linearization types
- builds linearizations with RGL functions
Thus we can write
concrete MathEng of Math =
open SyntaxEng, ParadigmsEng
in {
lincat
Prop = S ;
Set = CN ;
Elem = NP ;
lin
AndProp A B = mkS and_Conj A B ;
Nat = mkCN (mkA "natural") (mkN "number") ;
Even x = mkS (mkCl x (mkA "even")) ;
}
Functors
Since the Syntax API is implemented for all RGL languages, the code for MathEng can be ported to another language by just changing the language codes and the words and, if needed, the morphological functions called.
Thus we can write
concrete MathFre of Math =
open SyntaxFre, ParadigmsFre
in {
lincat
Prop = S ;
Set = CN ;
Elem = NP ;
lin
AndProp A B = mkS and_Conj A B ;
Nat = mkCN (mkA "naturel") (mkN "nombre" masculine) ;
Even x = mkS (mkCl x (mkA "pair")) ;
}
Notice that
- the implementation of
mkCNinSyntaxFrerendersNatin the correct word order, “nomber naturel”, - the definition of “nombre” adds gender explicitly, because the default gender of nouns ending with “e” is feminine.
Copying modules and changing language codes and words is a productive way to port GF grammars to new languages.
But there is something even better: functors, also known as parameterized modules.
A functor opens interfaces, which declare the types of functions but does not give their definitions.
The definitions are given in different instances of interfaces.
Thus the RGL Syntax is an interface, and SyntaxEng and SyntaxFre are its instances.
A functor for Math is a concrete syntax with the keyword incomplete:
incomplete concrete MathFunctor of Math =
open Syntax, Words
in {
lincat
Prop = S ;
Set = CN ;
Elem = NP ;
lin
AndProp A B = mkS and_Conj A B ;
Nat = mkCN natural_A number_N ;
Even x = mkS (mkCl x even_A) ;
}
In addition to the RGL Syntax, this module opens the interface Words:
interface Words =
open Syntax in {
oper
natural_A : A ;
number_N : N ;
even_A : A ;
}
with instances such as
instance WordsEng of Words =
open SyntaxEng, ParadigmsEng in {
oper
natural_A = mkA "natural" ;
number_N = mkN "number" ;
even_A = mkA "even" ;
}
and similarly for French. The final concrete syntaxes can now be written as instantiations of the functor:
concrete MathEng of Math = MathFunctor with
(Syntax=SyntaxEng),
(Words=WordsEng) ;
concrete MathFre of Math = MathFunctor with
(Syntax=SyntaxFre),
(Words=WordsFre) ;
Functors make it maximally easy to port GF grammars into new languages.
One advantage over just copying the code is that, when the abstract syntax is extended or changed, only the functor needs to be edited - and of course, if new words are added, the Words interface and its instances.
In addition to functors, GF grammars can be structured to modules in many different ways.
Maintaining a Words interface as above is usually not the best way to do this: it can be better to divide the abstract syntax into a syntax part and a lexical part, where the syntax part only needs the RGL syntax as its interface:
abstract MathSyntax = {
cat
Prop ; Set ; Elem ;
fun
AndProp : Prop -> Prop -> Prop ;
}
abstract Math = MathSyntax ** {
fun
Nat : Set ;
Even : Elem -> Prop ;
}
incomplete concrete MathSyntaxFunctor of MathSyntax =
open Syntax
in {
lincat
Prop = S ;
Set = CN ;
Elem = NP ;
lin
AndProp A B = mkS and_Conj A B ;
}
concrete MathSyntaxEng of Math = MathSyntaxFunctor with
(Syntax=SyntaxEng) ;
concrete MathEng of Math = MathSyntaxEng **
open SyntaxEng, ParadigmsEng in {
lin
natural_A = mkA "natural" ;
number_N = mkN "number" ;
even_A = mkA "even" ;
}
This examples shows module extensions marked with the operator **.
The difference between extensions and opening is that the extending module inherits all rules of the extended module.
Extensions create an inheritance hierarchy reminiscent of object-oriented programs, and designing it in a good way can require several rounds of trial and error. The Informath grammar is not an exception: its internal structure has changed several times during one year of continuous development. The most important principle is
- DRY: Don’t repeat yourself.
A corollary of this rule is
- The golden rule of functional programming: When you find yourself programming with copy and paste, write a function instead.
GF supports this with the usual constructs of functional programming, in particular the operdefinitions for auxiliary functions and libraries that can be opened.
Functors are an extension of it from expressions to modules: they are functions that produce modules, reducing the need to copy and paste.
Most users of Informath do not need to care about the internals of GF: they can work with a pre-compiled grammar (see next section) or at most on isolated lexicon modules defining new concepts for their own fields of mathematics.
Compiling GF
The GF software infrastructure consists of related functionalities:
- the GF shell, used for developing and testing grammars,
- the GF compiler, used for building a binary file for runtime usage,
- GF runtime interpreters, accessing the binary grammar from different programming languages, such as Haskell, Python, and C.
The runtime grammar is a single binary file, in our case Informath.pgf.
The Haskell runtime interpreter, which the Informath project uses, provides functions such as
linearize :: PGF -> Language -> Tree -> String
parse :: PGF -> Language -> Type -> String -> [Tree]
The compiler can also produce a Haskell module Informath.hs, which exports the abstract syntax as a generalized algebraic datatype.
This type is intensely used in the manipulations of syntax trees in Informath, especially semantics and NLG.
The MathCore language
The categories of MathCore
The syntactic categories of MathCore are defined in the module Categories. Here are some of the main ones:
category name linguistic type example
—-------------------------------------------------------------------
Exp expression NP (noun phrase) the empty set
Ident identifier Symb (symbol) x
Term symbolic term Symb x + 2
Int integer Symb 62
Jmt judgement Text N is a set.
Hypo hypothesis Text Assume A.
Kind kind CN (commoun noun) integer
Prop proposition S (sentence) 2 is even
Proof proof text Text By hypothesis h, B.
The “linguistic type” actually refers to a type in the GF Resource Grammar Library (RGL), which is used in the implementation of the grammars. The rough correspondences between Dedukti and MathCore are as follows:
Dedukti MathCore
-----------------------------------
Exp Exp, Kind, Prop, Proof
Hypo Hypo
Ident Ident
Jmt Jmt
Thus Dedukti’s Exp is divided between many categories of MathCore, and the task of the conversion is to decide which one to choose. This choice is based on symbol tables, which define mappings between Dedukti constants and MathCore functions. The symbol tables have entries such as
Int : integer_Noun
even : even_Adj
Eq : equal_Adj2
The left-hand side is a Dedukti constant and the right-hand side a MathCore function. These functions belong to some of the lexical categories of MathCore, which are listed in the following table:
category semantic type example
—-----------------------------------------------------------
Adj Exp -> Prop X is even
Adj2 Exp -> Exp -> Prop X is divisible by Y
Adj3 Exp -> Exp -> Exp -> Prop X is congruent to Y modulo Z
AdjC Exps -> Prop X and Y are distinct
AdjE Exps -> Prop X and Y are equal EQUIVALENCE
Dep Exp -> Kind root of X
Dep2 Exp -> Exp -> Kind interval from X to Y
DepC Exps -> Kind path between X and Y
Fam Kind -> Kind list of As
Fam2 Kind -> Kind -> Kind function from As to Bs
Fun Exp -> Exp the square of X
Fun2 Exp -> Exp -> Exp the quotient of X and Y
FunC Exps -> Exp the sum of X and Y
Label ProofExp theorem 1 .
Name Exp the empty set
Noun Kind integer
Noun1 Exp -> Prop X is a prime
Noun2 Exp -> Exp -> Prop X is a divisor of Y
Verb Exp -> Prop X converges
Verb2 Exp -> Exp -> Prop X divides Y
The category Exps contains non-empty lists of expressions. The last two expressions in a list are combined with the conjunction “and” and its equivalent in different languages. The token EQUIVALENCE does not belong to the output, but is shown here to distinguish AdjE from AdjC.
The Informath software provides several ways to define symbol table entries. The least programming-intensive is to parse them with the Informath grammar from examples showing how words and variables are combined. Thus the above symbol table could also be given as follows:
Int : "integer"
even : "X is even"
Eq : "X is equal to Y"
Parsing of example strings can be performed from English or from any other Informath language. They are converted to abstract syntax, which makes the symbol table entries available for all languages. The symbol table is also checked for arity and superficial type. For instance, a two-place Dedukti function producing a Prop can only be linearized with a lexical entry whole semantic category (in the table above) is Exp -> Exp -> Prop or Exps -> Prop.
The syntactic combination functions of MathCore
The abstract syntax of MathCore consists of around 70 combination functions for that build judgements, propositions, kinds, expressions, and proofs, ultimately from lexical items. The following is an overview of them, in the form of a context-free grammar pseudocode. The reader should keep in mind that
- each context-free rule corresponds to an abstract syntax function that operates on its nonterminals as argument and value types
- the righ-hand sides correspond to simple instances of the full linearization rules for English
- there rules do not show the variations in morphology and word order, which are defined in the source code by using the RGL
- since the definition is a functor, it also applies to other languages in Informath
Judgements and hypotheses
Starting from top down, we MathCore has rules for expressing definitions of different types of constants, with (definition) or without (axiom, postulate) proofs or other defining terms.
Jmt ::=
Label "." Hypo* Prop "."
| Label "." Hypo* Prop ("Proof ." Proof)? "."
| Label "." Hypo* Prop "if" Prop "."
| Label "." Hypo* "We can say that" Prop "."
| Label "." Hypo* "a" Kind "is a" Kind "."
| Label "." Hypo* Kind "is a basic type "."
| Label "." Hypo* Exp "is a" Kind ()"defined as" Exp)? "."
The hypotheses are either assumptions of propositions or declarations of variables.
Hypo ::=
"Assume that" Prop "."
| "Let" Ident "be a" Kind "."
Propositions
Propositions are the richest category, with functions corresponding to every constant of predicate logic as well as for atomic formulas built by means of predicates. We start with the logical constants:
Prop ::=
"we have a contradiction"
| Prop "and" Prop
| Prop "or" Prop
| "if" Prop "then" Prop
| Prop "iff" Prop
| "it is not the case that" Prop
| "for all" Kind Ident "," Prop
| "there exists a" Kind Ident "," "such that" Prop
These rules correspond one-to-one to a common formalization of logical constants in Dedukti. To prevent ambiguity, complex propositions (ones formed by logical constants) that appear as parts of other propositions are enclosed in brackets. Thus we have the following correspondances with Dedukti:
and A (or B C) <--> A and (B or C)
or (and A B) C <--> (A and B) or C
The brackets can be erased in the full Informath language, which provides other ways to avoid ambiguities.
The use of brackets is controlled by the flag isComplex in the linearization type of Prop:
lincat Prop = {s : S ; isComplex : Bool}
Now, in the natural language of mathematics, syntactic ambiguities do appear, and they are tolerated as long as the ambiguity is resolved by semantical means. For example,
- for all numbers $x$, $x$ is even or $x$ is odd
is syntactically ambiguous between
- for all numbers $x$, ($x$ is even or $x$ is odd)
- (for all numbers $x$, $x$ is even) or $x$ is odd
The latter alternative is rejected in type checking because it recognizes $x$ as an unbound variable in the second disjunct. Another way to make the first statement unambiguous even syntactically is to use a disjunction of adjectives:
- for all numbers $x$, $x$ is even or odd
This variant is provided in the full Informath language.
Atomic propositions are formed with separate rules for each category of predicates:
Prop ::=
Exp "is" Adj
| Exp "is" Adj2 prep Exp
| Exp "is" Adj3 prep1 Exp prep2 Exp
| Exp "and" Exp "are AdjC
| Exp "and" Exp "are AdjE
| Exp "is a" Noun1
| Exp "is a" Noun2 prep Exp
| Exp Verb
| Exp Verb2 prep Exp
The item prep in these rules, with or without a numeric index, refers to the inherent preposition of the predicate.
It can also be empty, as in the case of transitive V2.
Recall that every rule in the context free grammars we show corresponds to a GF abstract syntax function. The functions associated with lexican categories as the ones above will be called lexical application functions. Their types can be read from the context-free rules, and their abstract syntax names are formed from the lexical category and the value type; for example,
fun AdjProp : Adj -> Exp -> Prop
fun Adj2Prop : Adj2 -> Exp -> Exp -> Prop
fun AdjCProp : AdjC -> Exp -> Exp -> Prop
fun Verb2Prop : Verb2 -> Exp -> Exp -> Prop
and so on; notice that the lexical item itself is always listed as the first argument. Users of Informath do not need to see the abstract syntax function names except when changing the grammar or debugging the parser.
Kinds
Kinds correspond to common nouns (CN) in the RGL.
The can consist of several words, such as “prime number” and “element of $A$”.
However, in the latter case, a Kind expression needs to be divided into two parts in some constructions, such as when a variable is declared:
- for all elements $x$ of $A$, …
To enable this, we use a linearization type where the main noun and an adverbial part are separated:
lincat Kind = {cn : CN ; adv : Adv}
In the following grammar rules, we use the hyphen - to mark the boundary of these parts:
Kind :=
Kind Ident - "such that" Prop
| Noun -
| Fam - prep Kind
| Fam2 - prep1 Kind prep2 Kind
| Dep - prep Exp
| Dep2 - prep1 Exp prep2 Exp
| DepC - prep Exp "and" Exp
Notice that the second rule is actually a bit more complicated, because the CN-Adv boundary may occur inside the argument Kind, such as in
- for all elements $x$ of $A$ such that $x$ is rational, …
Expressions
Expressions in the sense of MathCore’s Exp category correspond singular terms in logic and noun phrases (NP) in the RGL.
They are formed by the following rules:
Exp :=
"$" Term "$"
| Name
| Fun prep Exp
| Fun2 prep1 Exp prep2 Exp
| FunC prep Exp "and" Exp
Notice that symbolic terms are enclosed in dollar signs when used as expressions.
This enables Informath to parse and generate LaTeX code as used in mathematical writing.
The Term category has just two rules in MathCore:
Term :=
Ident
| Int
But it is extended with many more rules in the full Informath.
There we will also extend the Exp category with rules that form quantifier phrases (such as “ever number”) and other expressions that are not singular terms in the logical sense.
Proofs and proof labels
The treatment of proofs is still largely work in progress in Informath. However, the following rules are enough to translate all proof objects that can be formed in Dedukti. They correspond to identifiers (either proof labels or singular terms), applications, and abstractions:
Proof :=
Proof* "by" ProofExp "."
| Hypo+ Proof
ProofExp :=
Label
| ProofExp "applied to" Exp+
| ProofExp "assuming" Hypo+
Special constants
The above categories of nouns, adjectives, and verbs cover a large part of verbal expressions of mathematical constants.
However, there are cases where this does not hold.
Such cases are taken care of GF functions that, instead of being constants of the lexical categories, take arguments and return values of the basic types, that is, Prop, Kind, Exp, and Proof.
Also Ident can occur as an argument, corresponding to a bound variable in higher-order abstract syntax.
We have already seen examples of this: the logical constants, such as
- Dedukti:
and : Prop -> Prop -> Prop - Informath:
CoreAndProp : Prop -> Prop -> Prop -
symbol table:
and : CoreAndProp - Dedukti
forAll : (A : Set) -> (Elem A -> Prop) -> Prop - GF:
CoreAllProp : Kind -> Ident -> Prop -> Prop - symbol table:
forAll : CoreAllProp
Another example is sum expressions:
- Dedukti :
sigma : Elem Num -> Elem Num -> (Elem Num -> Elem Num) -> Elem Num - GF:
SigmaExp : Exp -> Exp -> Ident -> Exp -> Exp - symbol table:
sigma : SigmaExp
The symbol table entries work if the Dedukti and GF types match. Run-time errors can occur if the Dedukti code contains function applications with different arities than those expected by the symbol table. If they are difficult to fix in the source code, using the empty symbol table should always produce failure-free verbalizations.
But one special case is possible to treat in a symbol table: dropping initial arguments. These are typically hidden arguments in another formalism, but Dedukti makes them explicit. For example, one might have
- Dedukti :
pair : (A : Set) -> (B : Set) -> Elem A -> Elem B -> Elem (Cart A B) - GF :
pair_FunC : Exp -> Exp -> Exp - symbol table :
pair : pair_FunC
In this case, the symbol table entry
#DROP pair 2
directs Informath to drop the first two arguments when converting a pair expression to a GF tree.
Dedukti expressions outside the grammar
To reach the full potential of informalization, all constants in the Dedukti file should have entries in a symbol table that maps them to lexical constants in the GF grammar. However, for the sake of completeness, Informath also has rules corresponding to raw Dedukti terms, that is,
- variables
- function applications whose heads do not have symbol table entries
- constants applied to unexpected numbers of arguments (e.g. as partical application)
- beta redexes (lambda expressions applied to arguments)
- lambda expressions not corresponding to higher-order abstract syntax
Such expressions are captured as catch-all cases of the translation from Dedukti to MathCore. The MathCore rules available for them are the following:
Prop ::=
Ident
| Ident "holds for" Exp+
Kind ::=
"element of" - Ident
| "element of" - Ident "of" Exp+
Exp ::=
Exp "applied to" Exp+
| "the function that maps" Ident "to" Exp
Needless to say, these rule produce rough “verbalizations” that can hardly be recognized as belonging to the informal language of mathematics.
Translation from Dedukti to MathCore
The translation from Dedukti to MathCore is defined in a Haskell module that maps Dedukti abstract syntax trees to MathCore abstract syntax trees. It is defined top-down starting from judgements, and descending to the smallest parts of them, guided by the symbol table.
The symbol table is provided by the user as a mapping from Dedukti constants to lists of GF functions. The table actually used in the translator also contains type information, which is derived from the GF grammar. This process can also fail, if there is a type mismatch between the Dedukti constant and the GF function.
The first step in translation is to select the form of judgement in MathCore that is used for the Dedukti judgement. Recall that MathCore has four kinds of judgement, defining or postulating either propositions (usually, predicates forming them), kinds, expressions, or proofs.
A Dedukti typing judgement (ignoring definition parts for the moment), has the form
Ident ":" Hypo* Exp
where the type expression can be divided into a hypothesis part and the part that follows them. This division is performed by following the syntax of the type as long as it has one of one of the forms $(x : A) \rightarrow B$ or $A \rightarrow B$. The extracted hypotheses form the context of the judgement. For example, the Dedukti judgement
prop30 : (n : Elem Nat) -> Proof (odd n) -> Proof (even (plus n 1)).
is analysed into
prop30 : (n : Elem Nat) (Proof (odd n)) ==> Proof (even (plus n 1)).
where we mark the end of the context part with ==>.
Judgements with defining parts (Dedukti’s def and thm) are analysed in the same way; they typically contain abstractions over variables for each type belonging to the hypotheses.
A look-up in the symbol table tries to find the MathCore function of Ident and its type.
If this fails, the translator tries another look-up at the head of Exp.
The default is Proof, because theorem statements are statistically more common than definitions, and their identifiers, names of theorems, are not always given grammar rules and therefore not included in symbol table.
Assuming that this is the case with prop30, the following MathCore text is generated.
- Prop30. Let $n$ be an instance of natural numbers. Assume that we can prove that $n$ is odd. Then we can prove that the sum of $n$ and $1$ is even.
The relevant part of symbol table used here is
Nat : natural_Noun
even : even_Adj
odd : odd_Adj
plus : plus_FunC
When generating MathCore, only the first GF function in each symbol table entry is used. The remaining ones are synonyms that can be used in full Informathl. Notice that one and the same MathCore function can be assigned to many Dedukti identifiers and therefore be ambiguous when translating natural language back to Dedukti. This ambiguity should ideally resolved by type checking, which should accept only one of the translations.
After selecting the form of GF judgement, the translator descends recursively to the parts of the hypothesis, the type, and the possible defining part. These parts are mostly built with function applications, and the translation uses the symbol table to identify the GF function and its type for each function head, to select the proper GF expression to translate the application. If we denote the GF function assigned to the constant $c$ by $c^{G}$, the lexical application function of its category by $c^{C}$, and the translation a complex expression $e$ as $e^{T}$, we can define the translation concisely as follows:
\[(c a_1 \ldots a_n)^{T} = c^{C} c^{G} a_1^{T} ... a_n^{T}\]If the Dedukti expression is not an application or an identifier found in the symbol table, the back-up rules are used to form a baseline translation.
If the Dedukti judgement has a definition part, this part is typically an abstraction expression with the same number of variable bindings as there are hypotheses. Here is an example:
def divisible : Elem Int -> Elem Int -> Prop :=
n => m => exists Int (k => Eq n (times k m)).
For such definitions, the variable names occurring in the hypotheses (if any) are unified with those in the bindings. The abstractions are not translated into explicit parts of the GF expression, but the variables occurring in the defining expressions get bound in the hypotheses:
- Definition. Let $n$ be an instance of integers. Let $m$ be an instance of integers. Then $n$ is divisible by $m$, if there exists an integer $k$, such that $n$ is equal to the product of $k$ and $m$.
The definition part may also consist of a set of rewrite rules. They are translated into a GF expression that linearizes into an itemized list of cases:
def plus : Elem Nat -> Elem Nat -> Elem Nat.
[m] plus m 0 --> m
[m, n] plus m (Succ n) --> Succ (plus m n).
translates to
- Let $x$ be an instance of natural numbers. Let $y$ be an instance of natural numbers. Then the sum of $x$ and $y$ is an instance of natural numbers. By cases:
- for $m$, the sum of $m$ and $0$ is $m$.
- for $m$ and $n$, the sum of $m$ and the successor of $n$ is the successor of the sum of $m$ and $n$.
Recall, once again, that the MathCore translations are designed to be very close to Dedukti. This makes them verbose and clumsy, but enable an accurate tracing of the translation process. Fluency is improved in the full Informath grammar, which introduces synonyms and shortcuts.
Translation from MathCore to Dedukti
Because of the close correspondence between MathCore and Dedukti, the translation is straightforward: its main ingredient is to suppress the additional syntactic information. Thus applications of adjectives, verbs, and nouns are all just applications of Dedukti identifiers. These identifiers are found by applying the symbol tables in an opposite direction. For example, the symbol table entry
even even_Adj
enables the translation of
- $8$ is even.
to
noLabel : Proof (even (nd 8)) .
Recall the use of the wrapper function nd converting digits to elements of the set Number.
When an English theorem statement has no label, the identifier noLabel is used in Dedukti.
If some of the words can be parsed in GF but are not found in the symbol table, the identifier UNDEFINED_<GFExp> is created.
The full Informath language
The extension of MathCore to full Informath enables the following steps. They are performed in the following steps, which come in an order where earlier steps can feed later ones. Consider an example where each of these steps produces a different expression, starting from
c : Proof (not (exists Nat (n => (and (prime n) (divisible n (times 2 3)))))).
The direct MathCore informalization (of the proposition, omitting the proof label) is
- We can prove that it is not the case that there exists a natural number $n$, such that ( $n$ is a prime number and $n$ is divisible by the product of $2$ and $3$ ).
The first step performs unpeeling of coercions and disambiguating parentheses:
- It is not the case that there exists a natural number $n$, such that $n$ is a prime number and $n$ is divisible by the product of $2$ and $3$.
The second step is to generate symbolic expressions with standard mathematical notations, which here affects just the last part:
- It is not the case that there exists a natural number $n$, such that $n$ is a prime number and $n$ is divisible by $2 \times 3$.
The third step is to generate synonyms of lexical functions, here “is prime” from “is a prime number”:
- It is not the case that there exists a natural number $n$, such that $n$ is prime and $n$ is divisible by $2 \times 3$.
The fourth step is to flatten conjunctions and disjunctions. It will convert propositions of the forms “A and (B and C)” and “(A and B) and C” to the flattened list conjunction form “A, B and C”. This step has no effect on our example.
The fifth step is the aggregation of shared parts of expressions. In our example, the variable $n$ is a shared subject of two adjectival phrases, and the sentence-level conjunction can be made into a conjunction of adjectives:
- It is not the case that there exists a natural number $n$, such that $n$ is prime and divisible by $2 \times 3$.
The next step is to form in situ quantifier phrase, which appear as syntactic arguments of predicates. This is possible only when the bound quantifier occurs exactly once in its scope; thus it is here made possible by aggregation:
- It is not the case that some natural number $n$ is prime and divisible by $2 \times 3$.
The next step is to remove variable symbols that do not appear anywhere except in their bindings:
- It is not the case that some natural number is prime and divisible by $2 \times 3$.
Finally, the awkward negation of the existential can be fused into a single quantifier phrase:
- No natural number is prime and divisible by $2 \times 3$.
Negations can also be fused with atomic predications, producing “$n$ is nof odd” from “it is not the case that $n$ is odd”; notice that aggregation gives more opportunities to this trnansformation.
In addition to the steps mentioned above, there is a growing number of syntactic structures that can produce more variants:
- discontinuous connectives, such as “both A and B” as a variant of “A and B”
- word order variations, such as “B if A” as a variant of “if A then B”, and post-quantifiers, “B for all x in A” as a variant of “for all x in A, B”
- pronouns and other anaphoric expressions: “it”, “its”, “the number”, etc, when their reference is unique in the context
The total effect of such transformations easily grows to hundreds of variants, and there is no upper limit. There is a rudimentary ranking that favours short verbalizations using the maximum of mathematical symbolism. On the other hand, it also gives penalties to ambiguous statements. A brief description of the best verbalization is: the shortest possible unambiguous one.
The semantics of Informath
The semantics of MathCore is given by its translation to Dedukti. MathCore has an open-ended lexicon, and lexical items get their semantics via symbol tables that map them to Dedukti constant. In the full Informath grammar, also the syntax is open-ended. To guarantee the preservation of meaning, every syntax extension must be equipped with a rule that maps it back to MathCore and thereby to Dedukti.
Symbolic terms and constants
Every entry in a symbol table must have a verbal function as its primary rendering, given right after the Dedukti function. Alternative verbalizations can also come from symbolic categories:
category semantic type example
—----------------------------------------------
Compar Term -> Term -> Formula <
Const Term \pi
Oper Term -> Term \sqrt
Oper2 Term -> Term -> Term +
A few constants of each of these categories are provided, dating back to an early version of the grammar. They permit the generation and parsing of common expressions and formulas such as
$a^{n} + b^{n} \neq c^{n}$
which LaTeX renders as
\[a ^ {n} + b ^ {n} \neq c ^ {n}\]Here, + and ^ belong to the category Oper2, whereas \neq is in Compar.
LaTeX notation defined by grammar comes with two issues:
- It is brittle, because mathematicians use LaTeX in different ways, for instance, adding spacing to make the layout prettier.
- All new notations must be included in the grammar, which must then be recompiled.
A more robust and scalable way to deal with LaTeX is hence to support the definition of arbitrary macros in symbol tables.
A macro symbol can then be included in the symbol table entry and its definition given in a separate #MACRO directive.
For example,
congruent : "X is congruent to Y modulo X" | \congruent
#MACRO \newcommand{\congruent}[3]{ #1 \equiv #2 \, \text{mod} \, #3 }
This works very well in informalization, whereas formalization only works for LaTeX code that is written by using the macros declared.
Generating symbolic notation
The generation of symbolic notation operates on two different categories: propositions (Prop), symbolized as formulas (Formula), and expressions (Exp), symbolized as terms (Term).
Only atomic propositions (formed by adjectives, nouns, and verbs) can currently be made symbolic, not logically complex ones.
This follows the traditional style of informal mathematics.
If the object language is formal logic, then it is of course possible to define complex formulas as expressions.
The generation is driven by symbol tables, which assign GF functions (including LaTeX macros) to Dedukti constants. Some of these functions, as well as all macros, are classified as symbolic. If we denote the set of symbolic functions for constant $c$ by $c^{F}$, the lexical application function of the category of such a function $f$ by $f^{C}$, and the set of symbolic variants of a complex expression $e$ as $e^{S}$ as we can define set of symbolic formulas and terms concisely:
\[(c a_1 \ldots a_n)^{S} = \{ f^{C} f s_1 ... s_n \mid f \in c^{F}, s_1 \in a_1^{S}, \ldots, s_n \in a_n^{S} \}\]Notice that the arities of Dedukti constants and their associated symbolic functions must match. This is guaranteed by the type checking of the symbol tables.
A built-in restriction of this definition is that symbolic terms (and formulas) can only have symbolic parts. This excludes, for the time being, some symbolic expressions with formal parts, such as comprehensions. It would probably not be difficult to add support them, but excluding them promotes a more succinct style.
Synonyms
Symbolic notations are a special case of synonyms: alternative expression for one and the same Dedukti constant. Verbal synonyms are given in symbol table similarly to symbolic ones. They are used in a similar way when generating alternative expressions:
\[(c a_1 \ldots a_n)^{V} = \{ f^{C} f v_1 ... v_n \mid f \in f^{G}, v_1 \in a_1^{V}, \ldots, v_n \in a_n^{V} \}\]Here, $c^{G}$ denotes the verbal functions (adjective, nouns, verbs) assigned to $c$, and $e^{V}$ contains both verbal and symbolic variants of $e$. The rationale is that a verbal function can always take symbolic expressions as arguments.